Fair to say that, based on the last week or so, neither my son nor I are going to make our millions on crypto.
ETH is down 10%
DOGE is down 13%
SUI is down 8%
What is quite interesting is just how unstable the currency is, which I kind of already knew. A few days ago ETH had jumped to a 1% increase for an hour or so. In general they’ve been bubbling along at around -10% since we bought them.
Anyway, it’s a long-term game (but I do have standing instructions from my son to sell his DOGE it if gets to +75% and he’s not around to ask).
Two or three years ago I switched my current account over to Starling Bank, and it has revolutionised the way I manage my money.
What initially drew me to Starling was the the ethical policies, 0% fees overseas usage (ATMs and paying by card), and – yes – because of the shiny fintech challenger bank thing, which I liked the look of. I was previously with Smile – which has a better ethical stance, but I didn’t like the fact it had to be bailed out by hedge funds. Of course, The co-op bank (and hence Smile) is now owned by the Coventry Building Society, which pushes it back up the ethical list. Triodos bank is also very near the top of my list (and I have savings accounts with them), but again their current account is just lacking features. I also liked the fact that Starling was founded by a woman.
What has kept me with Starling is that is it is absolutely fantastic product. The app is so easy to use, and the product has clearly been designed with a smartphone as the primary use case. This is in sharp contrast with the more traditional banks, who, it seems to me, have evolved online services as a way of providing the offline services online. It’s quite hard to put into words, but it’s the difference between starting from “we need to provide statements – ok, lets add that. We need to provide bank transfers, ok, lets add that” and “What would a bank account on a phone look like? What’s the landing page? what information needs to be in your face?”. Starling have clearly started with a clean slate and worked out what people want in a banking app – and have nailed it. I also really like the instant notifications – I don’t need to check my statements anymore each month, as I’ve reviewed each transaction along the way. Last “nice to have” is the spending breakdown; you can categorise each transaction (“groceries”, “health”, “coffee”) and see stats on what you are spending on what.
All that said, there is one killer feature for me which puts it in a different league: Spaces.
Spaces
Spaces are a way of dividing up or allocating money in your account – a bit like having another bank account, except it’s all the same physical account underneath. This may not seem like such a big deal, but it is has been a revolution to me. It doesn’t really give you anything you couldn’t do with multiple accounts and/or spreadsheets – except that you don’t need multiple accounts or spreadsheets!!
The important functionality is:
Spaces are named, and each has its own balance
Standing orders and direct debits can be paid from a space
You can set up virtual debit cards, which pay directly out of the space
You can automatically regularly transfer money in – either to top up to a set balance, or to pay in a set amount
The money in spaces is still physically in the same account, so attracts interest (or, at least, it did) and means you can go ‘overdrawn’ in your main balance without any fees, if there is enough money in spaces
If you don’t have enough money in a space to pay a standing order, it will notify you, as as long as your transfer in money the same day, the payment will be made.
It’s probably easiest to explain how I use them
I have a tithe space – every month 10% of my salary gets transferred in, and then subsequently most gets sent by standing order from this space to church, mission partners, or whatever. If any surplus builds up I can see it, and make sure I give it away at the appropriate opportunity.
I have a bills space – every month the space is topped up to the amount needed to cover all my regular monthly bills (council tax, mortgage, phones, electricity), and these bills are then paid over the month directly from the space.
I have a Christmas and presents space, which gets a transfer each month that builds up over the year. I use this money to buy presents throughout the year, and also is my budget for Christmas presents, food, cards, etc.
I have an internet virtual space, with a virtual card that I use for all my online shopping. The balance on this space is £0, and I transfer money into the space just before each purchase. This means I don’t need to worry about my card being cloned or abused – there is never any money ‘on the card’ to be stolen, and deleting and creating a new one is 3 clicks on the app.
I have a subscriptions space, where I have totted up all my yearly subscriptions (magazines, journals, etc), divided by 12, and transfer in that amount every month. All the subscriptions are then paid from this space as the year goes on.
I have spaces for other annual bills (such as house insurance) which again get topped up by 1/12th each month, and paid direct from the space each year.
I have a toy fund space where e.g. birthday money goes, which is just disposable income for video games, or whatever.
I have a general save space, where at the end of each month I can transfer in any positive balance in my main account.
I have a credit card space – every time I buy something on my credit card, I transfer that amount to this space. The full balance on the card is then paid off by direct debit.
And other ad-hoc spaces if there are any pots of money I want to keep separate.
What this gives me is a main balance which always reflects the amount of money I actually have to spend (once the essentials are covered), and all my money is one place. When I was with Smile, I had a tithe current account, and two or three savings account. But you had to remember which account number was which, and they each had different statements, chequebooks, cards, paying in slips, …
Cons
Of course, nothing is perfect, and there are some things I don’t like about Starling.
It is essentially app only – if my phone dies no bank account access
No chequebook (but then I can’t remember the last time I wrote a cheque)
The spending stats are a nice idea, but I don’t find they work very well with spaces
The statements are slightly awkward to access, and don’t have any reference to spaces
They no longer pay interest on their current account
That last one is actually a pretty big deal, as I will typically have several hundred pounds across my spaces. As they were all accruing interest, this was fine – no need for separate saving account.
Also worth saying it is online only – so no branches. Cheques can be paid in using the app, but cash has to go in via the Post Office.
So..
I really enjoy being a customer of Starling bank (and I have never previously said that about any bank). I am aware that all of the above assumes having enough money to make ends meet, and I don’t take that for granted.
But the app is a pleasure to use. I am on top of my money without any real ongoing effort now it’s all set up.
I made a few tweaks to my website over the weekend – chief one being to decrease the static page refresh time and update packages, but ran into all sorts of problems trying to build the Docker image.
Error: Could not load the "sharp" module using the linuxmusl-arm runtime
Possible solutions:
- Manually install libvips >= 8.15.3
- Add experimental WebAssembly-based dependencies:
npm install --cpu=wasm32 sharp
npm install @img/sharp-wasm32
- Consult the installation documentation:
See https://sharp.pixelplumbing.com/install
at Object. (/app/node_modules/sharp/lib/sharp.js:113:9)
at Module._compile (node:internal/modules/cjs/loader:1740:14)
at Object..js (node:internal/modules/cjs/loader:1905:10)
at Module.load (node:internal/modules/cjs/loader:1474:32)
at Function._load (node:internal/modules/cjs/loader:1286:12)
at TracingChannel.traceSync (node:diagnostics_channel:322:14)
at wrapModuleLoad (node:internal/modules/cjs/loader:234:24)
at Module. (node:internal/modules/cjs/loader:1496:12)
at mod.require (/app/node_modules/next/dist/server/require-hook.js:65:28)
at require (node:internal/modules/helpers:135:16)
> Build failed because of webpack errors
I have had this issue in the past (when I was first moving over to nextjs), but have built the site several times since then, but couldn’t for the life of me remember how to fix it. So I did all the usual stuff to fix it – cleared caches, updated packages… no joy. Builds and runs fine natively on the Pi itself, but the nextjs build fails in Docker with the above error no matter what.
After many hours going down a rabbit hole of node_modules (which I thought was being copied, and causing the issue), it turns out it was all to do with how I was building the container. I had experimented in the past with a fancy cross-platform build (so I could build the Pi container on my Windows PC), which I subsequently abandoned but left the instructions in my Readme.
docker buildx build --platform linux/arm/v7 .
Drop the platform specification, and it builds perfectly.
docker buildx build .
I’m not sure why this is – I know cross platform builds can be… interesting shall we say, but I didn’t think I was doing a cross platform build! Anyway, all working now. (The reason I have the command in my Readme is that I also tag it and push it up to Docker repository).
Incidentally, Stack Overflow was no help – so this is posted in case someone else benefits from my pain!
Ok, so that’s probably putting it a bit strongly. My younger son really wanted to buy some Dogecoin, so we finally relented and let him spend some of his Christmas money on cypto.
I decided for fun that I would match him in a different currency so we can have a mini competition.
He’s old enough to understand the risk associated – that he may lose all the money, is likely to get back less than he invested, and may not be able to sell it back to pounds when he wants to. Nevertheless he’s seem the 500% growth curve for Doge this year and wants in!
It’s as much about entertainment as anything else – the total amount we’ve spent between us is less than a computer game would cost, and I’m optimistic that they will be worth at least something in a few years time.
So, he has Dogecoin, I have Ether, and I also bought some Sui to make it a 3 horse race. 24 hours in, they are all still worth about what we paid after fees (ETH slightly up, DOGE and SUI slightly down).
Speaking of investment I also bought a modest number of Raspberry Pi shares at the IPO earlier this year. After the initial spike these settled down, but just before Christmas made a huge leap and have stayed up (+133%). I won’t lie and say I’m not tempted to sell, but I bought them to invest in a company I want to back, and plan to keep hold of them long term. It’s essentially part of my pension plan, but nice to see growth.
And I’ve started playing bass guitar (somewhat set back by putting a screwdriver through my finger the day after I bought it)
The real biggy for me was moving away from Virgin Media (they’ve been our Internet, phone, and TV provider since 2000, when it was NTL). I don’t buy into the fibre hype (coax cable, which is what Virgin ran from the cabinet to the router/modem, has plenty enough bandwidth) – but I’d got increasingly dissatisfied with the cost and the internet connectivity issues. Our monthly bill has gone from £59 for 125 MBps (asymmetric) broadband to £38 for 300 MBps symmetric (£32 for Zen, about £6 for VOIP). Not quite like for like, as Virgin included a set-top box, but not with any channels we watched. But in nearly a year we’ve had one short outage I think, but otherwise no degradation of service.
Didn’t manage to knock down our garage or build an extension. I also didn’t digitise any old negatives.
But did tick another thing off my bucket list, which was that we went on a Canal holiday which was also great.
This year? To be honest no big changes planned. We might sort out the garage, and we might start to think a bit more seriously about an extension.
Well, I am now the proud “owner” of a full electric car. I went for a BYD Atto 3 in the end, so I hope the Chinese government doesn’t decide to apply my full emergency brakes while I’m on the M5!
I say “owner” because I’m actually leasing it through work, so it’s technically a company car – but it’s mine in the sense that I’m paying for it and am the one on the insurance.
My venerable (well, 8 yo) Vauxhall has gone the way of motorway.co.uk, so now no petrol for me.
Initial thoughts – I like it, a lot. It’s so quiet and responsive, and now I’ve got the hang of not having to change gears or use the clutch it’s nice. The acceleration is something else, and it’s not even in sports mode.
With the Octopus Go tariff, my annual mileage (~6,000 miles) will cost about £75 – which is roughly the same as a full tank of petrol on the Vauxhall. I was filling up every 4 to 6 weeks probably, so that’s a win in my books. Plus filling up now happens overnight on the drive, not at a petrol station!
The quid pro quo is obviously the range. The theoretical range is 200 miles, but that’s downhill with the wind behind you on a warm day and running the battery completely flat. On a long journey, the distance between stops is more like 120 miles, given that you’re not supposed to run it below 20%, and charging is only fast to 80%. So broadly speaking it’s a 30-60 mins stop for every 2 hours of motorway driving. On my commute to Skipton (31 miles each way, with the A59 being closed) I get down to about 20% after 4 trips, i.e. 120 miles, but it is cold weather.
I guess this is where the rubber hits the road – almost every other aspect of an electric car is an improvement on petrol cars, but if I’m serious about wanting to reduce my environmental impact then actually having to be inconvenienced is when it counts.
We’re going to start having a “movie night” once a week, where we settle down on the sofa and watch a film together. It got me to thinking what we’d actually watch, so I thought I’d compile my ultimate film list.
The criteria are films which really one ought to have seen, and include classics (such as The Great Escape), films which broke new ground (such as The Matrix), films which have made their way into culture (such as ET) and finally films which I think are too good not to have seen (step forward The Princess Bride).
Missing from this list are most 18 rated films – I am excluding all films which are just unpleasant, or you leave feeling dirty and/or psychologically abused (Pulp Fiction, Blair Witch, Baby Driver – and most horror films. You get the drift).
Of course you will disagree – I will include films you wouldn’t agree with (step forward again Princess Bride), and exclude films you would think should be included – plus ca change. I’ll be the first to admit that some of these aren’t that good, but are too nostalgic for me not to include (The Black Hole, amongst others)
I’ve had half a stab at categorising as well – most films straddle categories, but it wouldn’t be me if there wasn’t some attempt at structure!
Musicals
Blues Brothers
Dirty Dancing
Grease
Sister Act
Annie
My Fair Lady
Oliver!
Little Shop of Horrors
Moulin Rouge
Singin’ in the Rain
The Fiddler on the Roof
The King and I
Mary Poppins
The Sound of Music
West Side Story
Wizard of Oz
Saturday Night Fever
Footloose
Rocky Horror Picture Show
plus Cabaret, Chicago, Guys and Dolls, Oklahama, High Society, ANnnie get your Gun, Calamity Jane, Joseph, Hello Dolly, Thoroughly Modern Millie, Porgy and Bess, Anything Goes, Phantom, South Pacific, Tommy, Carousel, …
Sci-fi / fantasy
Alien
Aliens
Blade Runner
Close Encounters of the Third Kind
Never ending Story
The Matrix
Jurassic Park
The Terminator 1 & 2
Star Wars episodes IV – VI
Star Trek (the 2009+ reboots are excellent, but II: Wrath of Khan, IV: Voyage Home, VI: Undiscovered country also all good)
The Final Countdown
ET: The Extra Terrestrial
2001: A Space Odyssey
Jumanji (the 2017+ sequels are really good as well)
I recently saw a question on The-Social-Media-Platform-Formerly-Known-As-Twitter asking about how people prepare for preaching a sermon. I wrote a short Twitter-esque reply, but thought it was worth a fuller treatment, in case either anyone is interested, or that it may even be helpful!
TL;DR
Know the context
Marinade in the scripture
Draw up a draft
Practice and refine
Pray and seek God at every stage!
And read these books:
“Misreading Scripture with Western Eyes” by Randolph Richards and Brandon O’Brien (IVP 2012)
“Short Stories by Jesus: The Enigmatic Parables of a Controversial Rabbi” by Amy-Jill Levine (HarperCollins 2015)
“Talk Like TED: The 9 Public Speaking Secrets of the World’s Top Minds” by Carmine Gallo (Macmillan 2014)
Know the context
My first step, as with any talk or presentation, is to establish the context. What sort of service is it? Who will be present? How long should the sermon be? Is there a particular theme? Is the Spirit been on the move in a certain aspect of the church? Is there a “party line” from the church leadership? At what point in the service is the sermon?
Some of these are potentially contentious or controversial, depending on your theology. For example I have a certain ambivalence to thematic preaching, as it’s very easy to squash in a token bible reading to fit what you want to talk about. I also think it assumes a pattern of church attendance (i.e. every week) which doesn’t always match up to the reality.
However I am also a firm believer in operating under authority, especially as an Associate Minister, and I will always seek to publicly back up the vicar/PCC. Of course, this is not blind or unqualified support – particularly thinking about the church’s history on abuse, most recently in the case of Soul Survivor and Mike Pilavachi. It also doesn’t mean being a “yes man”, and in private I will challenge and debate where I think we may be missing the mark. Anyway, I digress.
As some concrete examples, think of how sermon preparation would be different for these contexts:
A “normal” Sunday Holy Communion of 5 regular, committed, church members.
A “normal” Sunday Holy Communion of 150 regular, committed, church members.
A seeker service
An early morning service, with a 5 minute homily
An evening service, with an hour’s exposition on a bible passage
A funeral
A family service, with ages from 0 to 100+ present
A youth or student worship service
A sermon during an act of worship at a theological college
A prison
A school
… and so on
Reflection on the context should help to answer questions around:
The length of the sermon
The language to use
The depth of the content / theological assumptions
What level of interactivity
What props to use
Whether to use a PowerPoint type presentation
What form an application or response might take
What sort of humour/stories may be appropriate
What sort of humour/stories wouldn’t be appropriate
Marinade in the scripture
I try to start to think about the sermon at least two weeks before I’m preaching. I like to read the passage (or identify the theme) and mull it over. I try to come to it with fresh eyes – is there anything I’m skipping over. What are my cultural filters?
At this point I have to recommend a couple of books; “Misreading Scripture with Western Eyes” by Randolph Richards and Brandon O’Brien (IVP 2012), and “Short Stories by Jesus: The Enigmatic Parables of a Controversial Rabbi” by Amy-Jill Levine (HarperCollins 205). The second in particular isn’t very comfortable reading, but both certainly opened my eyes to some of the assumptions I (and our churches) make when reading scripture.
I sometimes do a lectio divino on the passage, to see what the Spirit might want to draw my attention to. Even if I’m not, I try to settle myself, ensure I have some quiet time and space, and just sit with the passage for a while, reading it over and praying through it.
I will sometimes dig out a commentary at this point, and will also reflect on resonances with other parts of the Bible. I will start to muse over whether there’s anything I’ve read which speaks to this passage. I will think about what quotes there might be. Or personal stories from my own life. I also start to keep my ears open for anything I come across which speaks to this passage. The internet has been a God-send for this, as I will often think “H’mm – I read something in Church Times about that”, and I can go and search it up.
As a slight aside, I keep a sermon scrapbook, and whenever I come across something which speaks to me in a newspaper or magazine, I cut it out and stick in the scrapbook. A lot of it I will may never use. My only tip is to make sure that you’ve either included the reference in the cutting, or write it alongside in the scrapbook.
Draw up a draft
This is probably what most people think of as writing a sermon. Turning the thoughts and musings into something ready to speak.
At this point I am just downloading ideas and following trains of thought, so see what emerges. I might identify areas I need to do a bit of research, have a look at different translations, read a commentary, maybe even dig into the Greek or Hebrew if I get very excited. Try and identify parallel passages.
The next step for me is to start to shape it, and how I do that depends greatly on the context. If it’s a ‘normal’ Sunday service I usually identify 3 major themes or points, each of which has 3 sub-points. I don’t necessary explicitly identify these when preaching, but I can hold 3×3 elements in my head, so can preach it with minimal notes. I quite like the following quote – I don’t know who said, and it’s far from the whole story, but it’s an interesting thought.
If you can’t keep your sermon in your head, how do you expect other people to?
This approach/structure comes from one of my favourite books on public speaking, “Talk Like TED: The 9 Public Speaking Secrets of the World’s Top Minds” by Carmine Gallo (Macmillan 2014). Once you get to longer than 10 or 15 minutes this technique runs out of steam a bit.
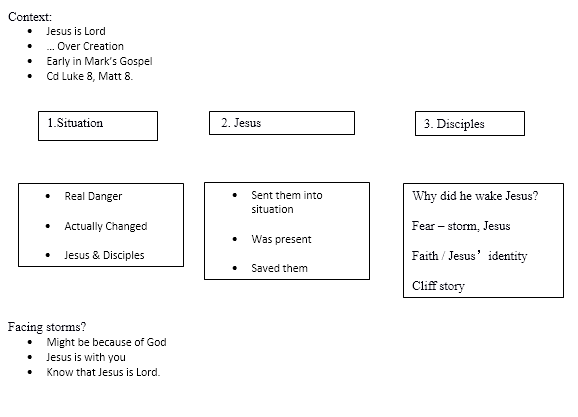
My notes when I’m using this technique look like this (for a sermon entitled “Jesus is Lord: Over creation – Mark 4:35-41”)
Another approach I’ve been experimenting with recently is sketchnoting, which is sort of like inverse note taking. This is much more of a journey, and is (obviously) far more visual than either a full script or the TED-like approach.
This ends up looking something like this:
Finally, if I get completely stuck, or is it a service where the language or timing is critical, I do write out the entire script verbatim.
So this is the opening of my sermon for our 2018 Remembrance Day service.
Pour out jug of sand
Never Again.
These were the words spoken one hundred years ago today, as the Armistice was declared, marking the end of the first World War. Of course at the time it wasn’t the first world war – it was The Great War – The War To End All Wars. And Never Again would future generations have to face the horror and pity of war.
Never Again.
And yet, just twenty years later, the world was at war again. Even today, UK armed forces are deployed around the world, and involved in ongoing wars in Iraq and Afghanistan.
Never Again?
In the great war, over 900,000 British soldiers died. Nine Hundred Thousand. That’s about the same number of grains of sand that I poured out when I first came up. Each individual grain of sand representing a British solider who died.
But of course, that’s only British soldiers. 10 million soldiers died in all.
Pour out rest of sand
…
Practice and refine
By this point I have the essence of the sermon.
What I do now is practice it – I mean literally shut myself in a room and deliver it. Make sure the timing is right. Make sure I know how I’m starting and ending it. Work out exactly how I’m going to tell that story, or assess if that joke is going to work. See if there’s bits which need to be cut or expanded upon. Try and form it into a cohesive whole.
Of course, if you are using a script, this is the editing phase of the script. But if I’m not using a script I rehearse it in my mind often right up to when I actually stand up to preach. Choice of phrase. Pause points. Which bits to repeat for emphasis.
For me, this is very much about the delivery.
In general terms, the longer the sermon the less “tight” it has to be. So if it’s an hour exposition, I will probably not rehearse it the whole way through, but will make sure I know what I’m saying for every verse, and then play it by ear on the day. For a ten minute sermon, I reckon you need to know the exact message and phrasing if you’ve any chance of keeping to time.
Incidentally don’t shy away from ruthless editing. My spiritual director once told me that he writes his sermon on Monday, sets it aside for the week, and then picks it up again on Friday and deletes half the words!
Pray and seek God at every stage!
This should go without saying – but ultimately preaching is huge privilege, and we’re seeking to share God’s heart with the congregation. That is an awesome responsibility, and not to be taken lightly. Throughout my entire sermon prep my dual prayer is “God help me”, and “may these words be your words”.
I hope that it is never my message when I preach, but God’s message through my words. Bishop Helen-Ann Hartley (now Bishop of Newcastle) once prayed this at the start the start of one of her sermons, and it has really stuck me with. It’s from memory, so is almost certainly a paraphrase.
May the written word and my spoken word bring us to you the living Word, Amen.



{kind=link}